
Network data centralization is the process of consolidating telemetry, configuration records, and operational data from distributed network nodes into a single, governed repository that gives IT teams unified visibility and control. The industry standard term for this architecture is centralized data management, and understanding it is critical for any organization running multi-site or multi-tenant networks. Platforms like Snowflake, Databricks, and Microsoft Fabric have made centralized data management accessible at enterprise scale. This article breaks down network data centralization explained from architecture to deployment, covering the tradeoffs, the hybrid alternatives, and the practical pitfalls that catch teams off guard.
What is network data centralization and how does it work?
Network data centralization consolidates distributed data into a single ecosystem. Every router, switch, firewall, and endpoint feeds telemetry into one governed repository instead of scattering records across isolated tools and local databases. That single repository becomes the authoritative source for monitoring, compliance reporting, and AI-driven analytics.
The core value is consistency. When all network data flows through one system, IT teams apply security policies, access controls, and data quality rules in one place. Fragmented tools create version conflicts and blind spots. A centralized model eliminates both. Platforms like Snowflake and Databricks are built specifically for this pattern, offering structured query access, role-based permissions, and audit trails across the full data estate.

Centralization also enables correlation. A firewall event logged in isolation means little. The same event correlated with authentication logs, bandwidth metrics, and device health data tells a complete story. That correlation is only possible when all data lands in the same governed store.
How does network data centralization differ from decentralized and federated architectures?
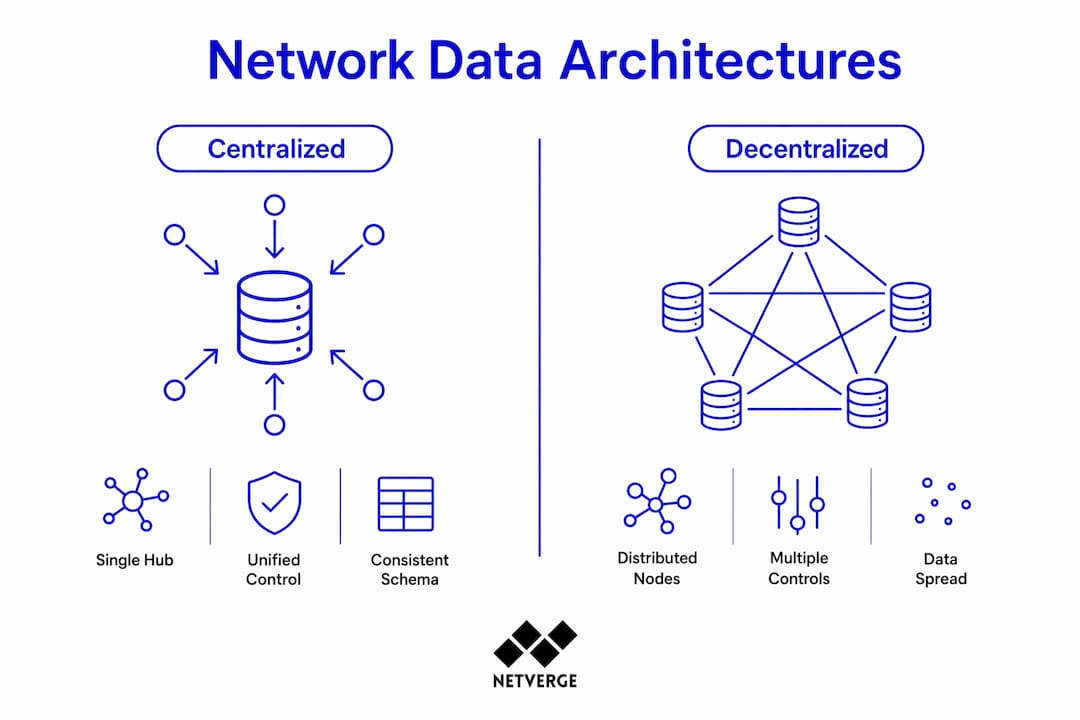
The three dominant architectures for network data management are centralized, decentralized, and federated. Each makes a different tradeoff between control, speed, and flexibility.
Centralized architecture places all data and control logic in one hub. IT teams manage one system, one schema, and one access policy. Configuration management is simple. The tradeoff is that the hub becomes a single point of failure and a performance bottleneck as data volume grows.
Decentralized architecture distributes both storage and control across multiple nodes. No single node holds all the data or makes all the decisions. This improves resilience and reduces latency for local operations, but it complicates governance. Enforcing a consistent security policy across dozens of autonomous nodes is operationally expensive.
Federated architecture sits between the two. A central body defines standards, but individual domains retain ownership and implement policies independently. The result is centralized governance with decentralized execution. Enterprises with regional compliance requirements, such as GDPR in Europe or HIPAA in healthcare, increasingly favor this model.
| Architecture | Data control | Storage location | Latency | Compliance fit |
|---|---|---|---|---|
| Centralized | Single authority | One repository | Higher for remote nodes | Strong, uniform enforcement |
| Decentralized | Distributed | Multiple nodes | Lower for local access | Complex, inconsistent |
| Federated | Shared governance | Domain-owned | Moderate | Strong, with regional flexibility |
The right choice depends on your network topology, regulatory environment, and AI workload requirements. For most MSPs and multi-location enterprises, the federated model offers the best balance.
What are the benefits and challenges of network data centralization?
Core benefits for IT operations
Centralized network data management delivers three concrete advantages: governance, security, and compliance enforcement. When all data flows through one system, IT teams apply access controls once and audit from one location. Regulations like GDPR and HIPAA require demonstrable data lineage. A centralized repository makes that audit trail straightforward.
Centralization also simplifies incident response. When an anomaly triggers an alert, analysts query one system rather than correlating logs from five separate tools. That reduction in query complexity directly cuts mean time to resolution. For MSPs managing dozens of client networks, that efficiency compounds quickly.
Challenges you cannot ignore
Centralized data governance improves compliance enforcement but creates access bottlenecks when scaling to thousands of users. Scaling centralized provisioning from 500 to over 5,000 consumers often leads to failure without hybrid approaches. That is not a theoretical risk. It is a documented failure pattern in large enterprise deployments.
Latency is the second major challenge. Centralized data warehouses often operate on batch-load cycles that introduce latency unsuitable for real-time AI decision-making. AI agents require data current at execution time. A warehouse refreshed every 15 minutes cannot support real-time anomaly detection or automated remediation.
The third challenge is the single point of failure risk. Without proper redundancy, failure of the central hub causes complete network downtime. Centralized control simplifies configuration management but significantly increases risk if high availability is not rigorously designed from day one.
- Governance: Unified policy enforcement across all network segments
- Security: Single perimeter to harden, monitor, and audit
- Compliance: Consistent data lineage for GDPR, HIPAA, and SOC 2 reporting
- Latency risk: Batch-load cycles delay data freshness for AI workloads
- Bottleneck risk: Provisioning at scale degrades without hybrid design
- Failure risk: Central hub outage affects the entire network without redundancy
"Centralization is often chosen for convenience but introduces chokepoints that threaten network resilience and openness." Techdirt
Pro Tip: Design redundancy into your central hub before you deploy, not after your first outage. Active-active failover for the central repository is the minimum acceptable configuration for production networks.
How do hybrid and federated models address centralization limitations?
Modern enterprises are not choosing between centralized and decentralized. They are building hybrid architectures that combine the governance benefits of centralization with the speed and resilience of distributed execution. This is the practical evolution of network data management for distributed environments.
Logical centralization through virtual semantic layers
Logical centralization through virtual semantic layers enables combining centralized governance with decentralized data execution. Virtual integration approaches offer a unified single source of truth without requiring physical data consolidation. The data stays close to where it is generated. The governance layer sits above it, applying consistent definitions and access rules.
This approach solves the latency problem directly. Data does not travel to a central warehouse before it is queryable. Local execution keeps response times low while the semantic layer maintains consistency across domains.
Four steps to implement a hybrid model
- Define your semantic layer first. Establish unified metadata definitions before connecting any data sources. Inconsistent definitions are the root cause of the visibility paradox described below.
- Assign domain ownership. Each network segment or business unit owns its data but operates within centrally defined standards. Alation's federated governance model formalizes this pattern.
- Build the central policy engine. Access controls, audit logging, and compliance rules live centrally. Execution happens at the domain level.
- Connect AI workloads to fresh data. Route real-time AI analytics to distributed execution nodes. Reserve the central warehouse for stable, repeated query patterns where Snowflake and Databricks outperform federated systems.
| Hybrid component | Function | Benefit |
|---|---|---|
| Virtual semantic layer | Unified metadata and definitions | Prevents data silos despite distributed storage |
| Domain ownership | Local data control within central policy | Reduces provisioning bottlenecks |
| Central policy engine | Governance and compliance enforcement | Consistent audit trail across all domains |
| Distributed execution | Local query processing | Low latency for AI and operational tools |
Successful enterprises increasingly adopt federated governance to maintain centralized policies with decentralized control, scaling across regions and domains without sacrificing compliance.
What practical pitfalls affect network data centralization deployment?
Deployment failures in centralized network data systems follow predictable patterns. Knowing them in advance is the difference between a successful rollout and a costly rebuild.
The visibility paradox
Improper metadata integration in centralized repositories leads to a visibility paradox where data silos persist despite centralization. You consolidate all your data into one system, then discover that inconsistent field names and conflicting definitions make the data unusable for cross-domain queries. Unified metadata and semantic definitions are necessary to prevent this outcome. Without a unified semantic layer, centralized repositories become ineffective silos due to inconsistent metadata and lack of integration across domains.
Chokepoint and lock-in risks
Centralized architectures inherently create chokepoints that are attractive targets for regulatory control and commercial exploitation. Chokepoints increase the risk of vendor lock-in, regulatory pressure, and reduced network openness. Tightly coupled platforms that own both the data pipeline and the query engine give you very little room to switch vendors without a full migration. Architect for portability from the start. Open standards for data formats and APIs reduce this exposure significantly.
Pro Tip: Audit your metadata schema before migration. Map every field name, data type, and definition across all source systems. Resolving conflicts before ingestion prevents the visibility paradox from forming.
The following pitfalls are the most common causes of centralization project failure:
- No redundancy plan: Central hub failure causes full network outage without active-active failover
- Metadata inconsistency: Conflicting field definitions create silos inside the central repository
- Latency blindness: Deploying AI workloads against batch-loaded data produces stale, unreliable outputs
- Vendor lock-in: Proprietary pipelines and query engines limit future flexibility
- Provisioning at scale: Access management processes designed for 500 users break at 5,000
For teams running AI-powered network management, the latency issue is especially critical. Real-time anomaly detection and automated ticketing require data that is current at execution time, not data that is 15 minutes stale from a batch cycle. Understanding why AI for network monitoring matters in 2026 starts with solving the data freshness problem at the architecture level.
The data acquisition pipeline feeding your centralized system determines the quality of every downstream AI output. Poor ingestion design produces unreliable analytics regardless of how well the central repository is governed.
Key takeaways
Network data centralization delivers the strongest governance and compliance outcomes when paired with a virtual semantic layer and hybrid execution model.
| Point | Details |
|---|---|
| Define architecture early | Choose centralized, federated, or hybrid based on your scale, latency needs, and compliance requirements. |
| Build redundancy first | Design active-active failover for the central hub before production deployment to avoid full network outage. |
| Unify metadata before migration | Resolve field name and definition conflicts across all source systems before ingestion to prevent data silos. |
| Use hybrid for AI workloads | Route real-time AI analytics to distributed execution nodes; reserve the central warehouse for stable queries. |
| Plan for provisioning scale | Access management designed for 500 users fails at 5,000 without a hybrid governance model in place. |
Why centralization architecture decisions matter more than the tools you pick
The debate over centralized versus federated network data architecture is real, but most teams focus on the wrong variable. They spend weeks evaluating platforms and almost no time defining their semantic layer. That is backwards.
I have seen organizations deploy Snowflake or Databricks with full executive support, only to end up with a central repository that nobody trusts because the field definitions from three source systems conflict with each other. The platform did not fail them. The architecture planning did.
The chokepoint risk is also underestimated. A centralized system that controls all data flow becomes a target, whether for regulatory pressure, vendor pricing leverage, or security attacks. That does not mean you should avoid centralization. It means you should design for portability and redundancy from day one, not as an afterthought.
The hybrid and federated models are not compromises. They are the mature evolution of centralized thinking. Keeping governance central while distributing execution gives you the audit trail and the speed. The data quality feeding your AI models depends entirely on how well you design that boundary between central policy and local execution.
The teams that get this right in 2026 will have a measurable operational advantage. The teams that treat centralization as a one-time migration project will rebuild in three years.
— Jim
Netverge's approach to centralized network visibility
IT teams managing distributed networks need more than a data warehouse. They need a platform that unifies monitoring, documentation, and AI-driven analytics into one interface without the latency and provisioning bottlenecks that plague traditional centralized systems.

Netverge consolidates network telemetry, device health, and event data into a single, AI-powered monitoring environment. The platform's network monitoring and observability tools give MSPs and multi-location enterprises real-time visibility without the batch-load delays that undermine AI workloads. Vergepoints provide physical observability at the edge, while the knowledge graph maintains a unified semantic layer across all connected sites. The tool sprawl problem that fragments network data across disconnected systems is exactly what Netverge is built to solve.
FAQ
What is network data centralization?
Network data centralization is the consolidation of telemetry, configuration records, and operational data from distributed network nodes into a single, governed repository. It gives IT teams unified visibility, consistent policy enforcement, and a single audit trail across all network segments.
Why does centralized network data improve compliance?
A centralized repository applies access controls and audit logging in one place, making it straightforward to demonstrate data lineage for regulations like GDPR and HIPAA. Distributed systems require correlating records from multiple locations, which increases compliance complexity and audit risk.
What is the main risk of centralized network architecture?
The primary risk is a single point of failure. Without active-active failover, central hub failure causes complete network downtime. Centralized systems also create chokepoints that attract regulatory pressure and vendor lock-in.
How does a federated model differ from full centralization?
A federated model keeps governance and policy definitions central but allows individual domains to own and execute against their own data. This reduces provisioning bottlenecks and supports regional compliance requirements while maintaining a consistent audit trail.
Can centralized systems support real-time AI analytics?
Standard centralized warehouses running on batch-load cycles cannot reliably support real-time AI decision-making. Hybrid architectures that route AI workloads to distributed execution nodes while maintaining a central governance layer are the recommended approach for AI-ready network data management.