
Traditional network monitoring tools were built for a simpler era. Fixed thresholds, manual log reviews, and rule-based alerting cannot keep pace with modern distributed infrastructure. If you manage a network spanning multiple sites, cloud workloads, and hybrid endpoints, you already know the gap between what your tools detect and what is actually happening. Understanding why use AI for network monitoring starts with recognizing that speed and scale have outgrown human-only approaches. AI does not just add automation. It changes how visibility, detection, and response actually work.
Table of Contents
- Key takeaways
- Why use AI for network monitoring today
- AI-driven root cause analysis
- Predictive analytics and automated response
- Challenges and best practices
- Real-world AI monitoring examples
- My honest take on AI and network monitoring in 2026
- See AI-powered monitoring in action with Netverge
- FAQ
Key takeaways
| Point | Details |
|---|---|
| AI enables real-time detection | AI correlates telemetry continuously, catching threats during their occurrence rather than in post-event log reviews. |
| Root cause precision improves | AI baselines normal behavior and traces symptoms back to the source across multiple network stack layers. |
| Predictive analytics reduce downtime | AI identifies early warning signals for hardware failure and bandwidth saturation before they affect users. |
| Human oversight remains critical | AI deployments require guardrails, audit trails, and human judgment to prevent error propagation. |
| Data quality determines AI accuracy | Missing telemetry signals directly limit diagnostic confidence, making complete data ingestion non-negotiable. |
Why use AI for network monitoring today
The shift from periodic log analysis to continuous real-time monitoring is the most consequential change AI brings to network operations. Traditional tools wait for a threshold breach to fire an alert. AI builds a behavioral baseline and flags deviations the moment they appear, whether or not they match a known signature.
This matters because modern threats do not announce themselves. Lateral movement, credential misuse, and insider threats often look like normal traffic until a pattern emerges across multiple signals. AI systems correlate packets, endpoints, and cloud signals instantly, identifying suspicious activity while it is happening rather than hours later during a review cycle.
Alert fatigue is a real operational cost. When analysts receive hundreds of low-fidelity notifications per shift, meaningful signals get buried. AI reduces alert noise by learning what normal looks like and surfacing only significant deviations, which cuts irrelevant alerts and speeds triage without requiring more headcount.
Here is what AI-driven monitoring covers that rule-based tools routinely miss:
- Behavioral baselining across users, devices, and traffic flows over time
- Multi-source telemetry correlation combining network packets, endpoint telemetry, and cloud workload signals
- Unknown failure mode detection that goes beyond pre-written alert rules
- Lateral movement identification by flagging unusual internal communication patterns
- Insider threat signals based on deviation from established behavioral norms
Pro Tip: Set your AI monitoring platform to alert on rate of change, not just absolute thresholds. A CPU that climbs from 20% to 80% in two minutes is far more meaningful than one sitting at 75% all day.
AI-driven root cause analysis
Traditional threshold-based alerting tells you a problem exists. AI-driven root cause analysis tells you why the problem exists and where it actually started.
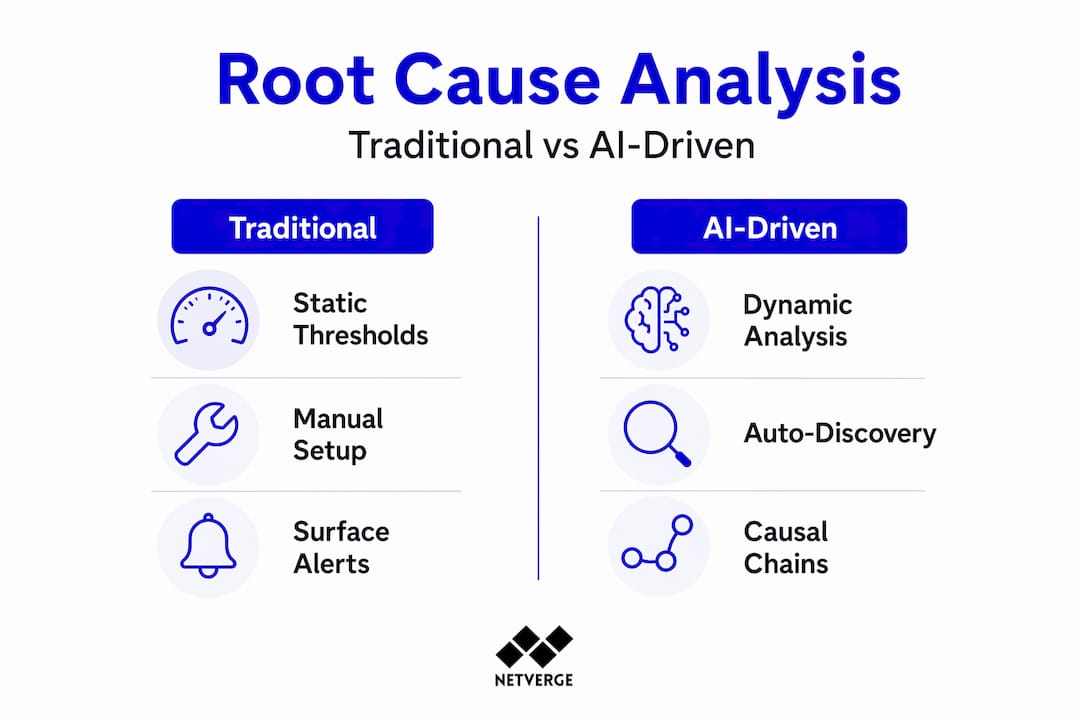
The distinction matters more than most teams realize. A slow application response might surface as a ticket against the app server when the actual cause is a misconfigured switch three hops away. AI builds continuous baselines and traces symptoms back through the network stack to isolate origin points. It does not just see the fire. It maps the path back to the spark.
Graph neural network approaches take this further. Topology-aware graph models combined with causal chains and evidence timelines produce diagnostic outputs that are both accurate and explainable. This explainability is not a nice feature. It is what builds operator trust and makes selective automation safe.
| Dimension | Traditional monitoring | AI-driven monitoring |
|---|---|---|
| Alerting method | Static threshold breaches | Behavioral deviation from learned baselines |
| Root cause identification | Manual log correlation by analysts | Automated topology-aware causal tracing |
| Time to resolution | Hours to days depending on complexity | Minutes with continuous correlation |
| False positive rate | High due to rigid rules | Reduced through behavioral context |
| Coverage | Configured devices and known signatures | Auto-discovered topology and unknown anomalies |
Traditional tools also require you to manually configure thresholds for every monitored device. AI auto-discovers network topology, builds baselines, and adjusts detection parameters dynamically as your environment changes. For MSPs managing dozens of client networks, that reduction in manual setup overhead is operationally significant.
Pro Tip: When evaluating AI root cause tools, ask vendors specifically how they handle missing telemetry. Systems that cannot actively fetch incomplete data lose their evidence chain and produce unreliable diagnoses.
Predictive analytics and automated response
AI does not only detect problems. It anticipates them. This predictive capability is one of the strongest arguments for adopting AI in network operations, particularly for teams managing uptime SLAs.

Predictive analytics work by identifying early warning patterns that precede known failure types. A network switch showing micro-bursts of packet loss days before a full failure. A WAN link trending toward saturation two weeks before a reported slowdown. A storage node with read latency gradually climbing outside its normal range. AI catches these signals before they become incidents.
Automated response adds another dimension. When AI detects a confirmed threat or a clearly defined failure condition, it can execute pre-approved remediation steps without waiting for a human to review a ticket. Common examples include:
- Automatically isolating a device exhibiting ransomware propagation behavior from the rest of the network segment
- Blocking a suspicious external IP that has triggered multiple correlated threat signals across endpoints and firewall logs
- Rerouting traffic around a degraded link based on real-time performance telemetry
- Triggering configuration backups when a change event is detected on a critical device
- Escalating prioritized incidents to the right team with full diagnostic context already attached
AI in security operations centers improves operations by filtering false positives and grouping alerts into prioritized incidents with contextual detail. This shifts analyst time from triage to resolution.
Human judgment still belongs in this process. Enterprise AI deployments require governance, guardrails, audit trails, and clear boundaries on what actions AI can execute autonomously. The right model is not full autonomy. It is AI handling well-defined, lower-risk responses while escalating ambiguous or high-impact decisions to operators.
Challenges and best practices
AI monitoring is not plug-and-play. Several real-world factors limit its effectiveness, and knowing them upfront saves you from painful rollout mistakes.
The most underappreciated limitation is telemetry gaps. Missing telemetry is a primary limitation for AI root cause analysis. When a system cannot access the data it needs to complete a diagnostic chain, it either guesses or fails silently. Both outcomes erode trust. Effective AI monitoring requires comprehensive data ingestion from every relevant source and fallback mechanisms to actively retrieve missing signals.
Latency in the data pipeline is equally critical. Real-time telemetry timeliness is what separates AI that detects threats in progress from AI that surfaces them after the damage is done. If your data pipeline introduces 10-minute delays, your "real-time" monitoring is not real-time. Low-latency ingestion is a prerequisite, not an optional optimization.
Key best practices for successful AI network monitoring deployments:
- Audit your telemetry coverage first. Map every data source before deployment. Gaps you discover in planning are far cheaper than ones you discover during an incident.
- Start with detection, then expand to automation. Let AI prove its accuracy in your environment before granting it remediation authority.
- Require explainable outputs. AI that surfaces a root cause diagnosis should show its reasoning. Black-box outputs that operators cannot verify will not get acted on.
- Build human-in-the-loop controls. Define clear escalation paths and human approval requirements for consequential automated actions.
- Monitor the AI itself. Track false positive rates, missed detections, and diagnostic confidence scores over time to verify model performance.
Real-world AI monitoring examples
The advantages of AI in network operations are easier to evaluate when you look at specific deployments rather than general claims. These examples show what AI actually delivers in production environments.
- Juniper's Mist AI uses a virtual network assistant to automate root cause analysis across Wi-Fi and wired infrastructure. It correlates client experience metrics with infrastructure telemetry to identify whether a connectivity complaint traces back to the radio, the switch, or an upstream link.
- Datadog's Watchdog AI engine correlates infrastructure telemetry across services to surface root causes during scaling events. Instead of engineers manually cross-referencing dashboards, Watchdog surfaces what changed and what correlated with a performance degradation.
- Dynatrace's AI provided continuous visibility during Azure scaling operations, automatically mapping new resources as they came online and detecting anomalies in freshly provisioned infrastructure without manual configuration.
- Anodot's AI analytics engine provided early alerting on business-impacting anomalies before they escalated, using time-series analysis across high-cardinality metric streams that traditional monitoring tools could not process at scale.
- LogicMonitor's AI auto-discovery and dynamic thresholding significantly reduced alert noise for enterprise teams, allowing analysts to focus on genuine incidents rather than configuration drift generating irrelevant notifications.
For a closer look at what detection accuracy looks like across real deployments, the anomaly detection examples from Netverge's blog covers practical scenarios worth reviewing.
My honest take on AI and network monitoring in 2026
I've watched a lot of teams deploy AI monitoring tools expecting them to be a replacement for operational discipline. They are not. What I've found consistently is that AI amplifies whatever foundation is already in place. If your telemetry is incomplete, your documentation is out of date, and your escalation paths are unclear, AI will surface those gaps faster than any audit.
The teams that get the most value from AI monitoring are the ones that treat it as an augmentation layer, not a substitute for understanding their own infrastructure. I've seen platforms produce impressive root cause outputs only for operators to distrust them because they didn't understand the diagnostic logic. That's not an AI problem. That's an explainability and onboarding problem.
My advice for 2026: start by getting your telemetry pipelines right and your monitoring trends for the year mapped before you layer in AI decisioning. Prove accuracy in your environment before expanding to automated remediation. And do not skip the governance framework. AI agents that can reconfigure devices or isolate hosts need audit trails and human approval thresholds that your operations team actually trusts.
The future of autonomous network management is real. But it is built on incrementally earned trust, not a single deployment decision.
— Jim
See AI-powered monitoring in action with Netverge
Netverge is built specifically for the operational challenges covered in this article. The platform unifies real-time telemetry ingestion, AI-driven anomaly detection, automated ticket triage, and root cause analysis into a single interface. For MSPs managing multiple client environments and enterprises running distributed infrastructure, Netverge replaces fragmented tooling with a consolidated AI-powered ecosystem.

Netverge's AI network monitoring platform gives network administrators full-stack visibility with behavioral baselining, predictive alerting, and autonomous AI agents that diagnose and respond to issues without waiting for manual review. Purpose-built for MSP network operations and enterprise environments, Netverge connects observability with documentation, ticketing, and automated workflows. Request a demo to see how it performs against your current monitoring setup.
FAQ
What is AI in network management?
AI in network management refers to the use of machine learning and behavioral analytics to automate monitoring, anomaly detection, root cause analysis, and predictive alerting across network infrastructure. It replaces static rule-based tools with systems that learn normal behavior and adapt continuously.
How does AI reduce alert fatigue in network monitoring?
AI learns baseline behavior across devices and traffic patterns, then surfaces only significant deviations rather than firing on every threshold breach. This cuts irrelevant alert volume and gives analysts fewer, higher-quality signals to act on.
What are the main advantages of AI in network operations?
The core advantages include continuous real-time detection, faster root cause identification, predictive analytics for failure prevention, automated response to confirmed threats, and reduced manual configuration overhead through auto-discovery and dynamic baselining.
Why do AI monitoring deployments fail?
Most failures trace back to incomplete telemetry coverage, high-latency data pipelines, or insufficient human oversight. When AI lacks complete data or acts without governance guardrails, diagnostic accuracy drops and operator trust erodes quickly.
How do AI agents fit into IT support workflows?
AI agents in IT support handle structured, repeatable tasks such as ticket triage, alert grouping, and first-response remediation. They escalate ambiguous or high-impact decisions to human operators, acting as a force multiplier rather than a full replacement for analyst judgment.