
Network operational workflow is defined as the structured set of processes, tools, and governance practices organizations use to continuously monitor, manage, and optimize network infrastructure. Known formally as NetOps, this framework covers monitoring, incident response, configuration management, capacity planning, performance optimization, and security enforcement. For IT teams managing distributed environments, understanding network workflows is the difference between proactive control and reactive firefighting. NOC teams, automation platforms, and runbooks are the three core instruments that make this framework function at scale.
What is network operational workflow and why does it matter?
A network operational workflow is the end-to-end sequence of activities that keeps network infrastructure running reliably. It defines who does what, when, and with what tools, from the moment a telemetry signal fires to the moment an incident is closed and documented. Without this structure, teams default to ad hoc responses that produce inconsistent outcomes and accumulate technical debt.
The importance of network workflows becomes clear when you consider what breaks without them. Configuration changes made without peer review cause outages. Incidents without documented response steps take longer to resolve. Performance degradation goes undetected until users complain. A well-defined network operations framework prevents all three failure modes by creating repeatable, auditable processes that scale across teams and locations.

For MSPs and multi-location enterprises specifically, operational workflow in networking is not optional. Managing dozens or hundreds of sites without standardized processes means every engineer solves the same problem differently. That inconsistency multiplies risk. A shared workflow architecture eliminates that variance and makes the entire operation measurable.
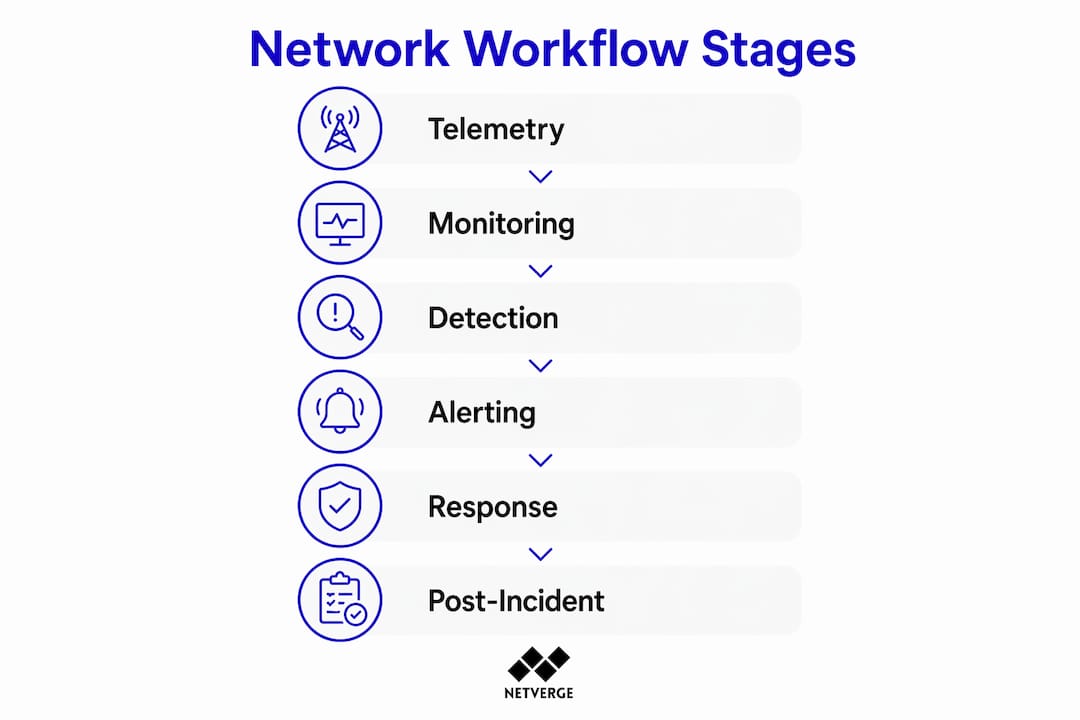
What are the primary stages of a network operational workflow?
The telemetry-to-action pipeline is the backbone of any mature network operational workflow. It moves from raw data collection through visibility, detection, remediation, and continuous improvement. Each stage has distinct inputs, outputs, and responsible parties.
- Telemetry data collection. Logs, metrics, SNMP traps, NetFlow records, and API-sourced data are gathered from routers, switches, firewalls, and applications. This raw data is the foundation of every downstream decision.
- Centralized monitoring and visibility. A single-pane-of-glass platform aggregates telemetry into dashboards that surface anomalies, threshold breaches, and topology changes. Without centralized visibility, correlation across devices is impossible.
- Incident detection and automated alerting. Threshold-based and AI-driven detection engines identify deviations from baseline. Alerts are routed to the appropriate team or automation agent based on severity and category.
- Remediation. Depending on governance policy, remediation is either automated for low-risk conditions or escalated to a human engineer for high-risk scenarios. Both paths follow predefined steps documented in runbooks.
- Post-incident analysis and continuous optimization. After resolution, teams conduct structured reviews to identify root causes and update workflows, runbooks, and monitoring thresholds accordingly.
Pro Tip: Link your network performance management workflow directly to your alerting system so engineers can access the correct remediation steps from the alert itself, not from a separate documentation portal.
The post-incident loop is the stage most teams skip. Treating it as optional means the same incidents recur, and the workflow never matures. Build it into your operational cadence as a non-negotiable step.
How does change and configuration management integrate into network workflows?
Change management is the control layer that prevents network modifications from becoming outages. Effective network change management requires scope and risk analysis, peer review, pre-deployment testing, implementation, validation, and documentation updates. Each step is a gate, not a suggestion.
The critical elements of a change management workflow include:
- Scope and risk analysis. Define exactly what is changing, which devices are affected, and what the blast radius of a failure would be.
- Peer review. A second engineer reviews the change plan before any configuration is touched. This catches logic errors that the author cannot see.
- Pre-deployment testing. Where possible, validate changes in a lab or staging environment. For production-only changes, define a test sequence that confirms expected behavior immediately after implementation.
- Maintenance windows and communication. Notify all affected stakeholders before changes begin. Unannounced changes that cause brief disruptions erode trust even when technically successful.
- Validation and documentation. After implementation, confirm the change produced the intended result. Update configuration records, topology diagrams, and the change log immediately.
"The operational change loop integrates planning, communication, validation, and rollback so outages are minimized and changes are safer." The change management principles that underpin this loop treat rollback not as a fallback but as a pre-planned, tested procedure defined before the change window opens.
Automation plays a specific role here. Low-risk changes such as VLAN additions or ACL updates on non-critical segments can be automated under policy governance. High-risk changes affecting core routing or security infrastructure require human sign-off at every gate. Mixing these categories without clear criteria is where automation governance breaks down.
What role do runbooks and documentation play in network workflows?
Runbooks and playbooks are related but distinct. A playbook defines the strategic response to a category of incident. A runbook provides the specific, numbered steps an engineer executes for a defined trigger condition. Both are necessary; neither replaces the other.
| Element | Runbook | Playbook |
|---|---|---|
| Scope | Single, specific procedure | Broad incident category |
| Format | Numbered steps with verification | Decision trees and escalation logic |
| Audience | On-call engineer during incident | Team lead or incident commander |
| Update frequency | After every relevant incident | Quarterly or after major events |
An effective runbook contains six elements: the trigger condition that activates it, prerequisites the engineer must confirm before starting, numbered steps with expected outputs at each stage, verification checks to confirm success, a rollback procedure if the steps fail, and escalation paths if the runbook does not resolve the issue. Missing any one of these elements degrades the runbook's reliability under pressure.
Runbook discoverability is an underappreciated operational control point. If an engineer cannot find the correct runbook within 60 seconds of an alert firing, the document might as well not exist. Runbooks must be linked directly from alerts and stored in a location accessible even if the primary incident management platform is down. Version control is equally non-negotiable. An outdated runbook followed precisely can make an incident worse.
Pro Tip: Store runbooks in a version-controlled repository such as Git and mirror them to a static site or offline-accessible format. When your incident platform fails, and it will, your runbooks need to be reachable independently.
Operational documentation is an active control element, not a passive task. It maintains traceability, auditability, and operational clarity between teams, especially during shift handoffs where context loss is a primary cause of extended incidents.
How do modern NOCs implement automation governance in network workflows?
Modern Network Operations Centers operate on a hybrid human-agent model. Fully manual NOCs cannot scale to the telemetry volumes generated by distributed infrastructure. Fully autonomous operations introduce unacceptable risk without mature governance. The answer is a structured division of labor governed by explicit policy.
Governance models in NOCs use four layers to keep automation safe and accountable:
- Intent layer. Defines what the automated agent is authorized to accomplish. Intent is expressed as a policy statement, not a script.
- Cognitive orchestration. The agent reasons about the current network state and selects actions within its authorized scope.
- Policy enforcement. Before any action executes, a policy engine validates that the action falls within defined boundaries and does not conflict with active change freezes or maintenance windows.
- Runtime enforcement. Real-time checks confirm that executing actions produce expected telemetry changes. Unexpected results trigger immediate escalation to a human engineer.
Safe automation in NetOps starts with low-risk tasks under policy governance, with explicit escalation for high-risk cases. This phased approach builds operational confidence before expanding automation scope. Teams that attempt to automate high-risk remediation before establishing governance frameworks consistently produce outages that manual operations would have avoided.
Structured handoff protocols are equally critical. When an automated agent reaches the boundary of its authority, the handoff to a human engineer must include full context: what was detected, what actions were taken, what the current state is, and what the recommended next step is. A handoff without this context forces the engineer to reconstruct the situation from scratch, adding minutes to resolution time during high-pressure incidents.
AI agent workflows require explicit intent programming, evaluation criteria, and risk boundaries to safely automate network operations at scale. Organizations that treat AI agents as general-purpose tools without defined constraints will encounter boundary violations that damage both infrastructure and operational trust.
Key takeaways
A network operational workflow succeeds when telemetry collection, governed automation, and version-controlled runbooks operate as an integrated system rather than isolated practices.
| Point | Details |
|---|---|
| Define workflow stages explicitly | Map each stage from telemetry collection to post-incident review with clear owners and outputs. |
| Gate every change with peer review | Scope analysis and peer review before implementation prevent the majority of change-related outages. |
| Link runbooks directly to alerts | Runbook discoverability during incidents directly reduces mean time to resolution. |
| Govern automation by risk tier | Automate low-risk tasks under policy constraints; require human sign-off for high-risk changes. |
| Treat documentation as a control | Version-controlled, accessible documentation maintains auditability and enables effective team handoffs. |
Why most workflow failures are governance failures, not technology failures
I have reviewed network operations setups across MSPs and enterprise IT teams for years, and the pattern is consistent. When a workflow breaks down, the root cause is almost never the monitoring tool or the automation platform. It is a governance gap. Either the intent was never defined clearly, the runbook was not updated after the last incident, or the automation boundary was drawn too broadly because someone wanted to move fast.
The teams that get this right share one habit: they treat the workflow itself as a living document. They run sovereignty reviews, which are structured sessions where they audit what their automated agents are actually doing versus what they were authorized to do. They update runbooks within 24 hours of any incident where the existing runbook fell short. They define rollback criteria before every change window, not during it.
The uncomfortable truth about network workflow optimization is that the technology is the easy part. Platforms like Netverge can surface telemetry, correlate anomalies, and execute governed automation. What no platform can do is substitute for the organizational discipline of defining intent, reviewing outcomes, and updating documentation consistently. The teams that invest in that discipline get compounding returns. Every incident makes the next one faster to resolve. Every post-incident review makes the workflow more precise.
If you are building or rebuilding a network operations framework, start with runbooks before automation. Get your documentation right, link it to your alerts, and put it under version control. Then layer automation on top of a foundation that is already working. The reverse order, automating first and documenting later, produces systems that nobody fully understands and nobody fully trusts.
— Jim
How Netverge supports your network operational workflow

Netverge unifies the components that network operational workflows depend on into a single AI-powered platform. Its real-time network monitoring provides centralized telemetry visibility across distributed sites, with anomaly detection and automated alert triage built in. For teams ready to govern automation, the Visual AI Agent Designer lets you build no-code workflow automations with explicit intent definitions, policy constraints, and escalation paths. MSPs and multi-location enterprises use Netverge to replace fragmented tools with one interface that covers monitoring, documentation, ticketing, and governed automation. Start a free trial or request a demo at netverge.com.
FAQ
What is the difference between a runbook and a playbook in network operations?
A runbook provides numbered, step-by-step instructions for a specific trigger condition, while a playbook defines the broader strategic response to a category of incident. Both are required for a complete network operations framework.
How does automation governance work in a NOC workflow?
Governance layers define what automated agents are authorized to do, enforce policy boundaries before actions execute, and escalate to human engineers when conditions fall outside defined parameters. This structure keeps automation safe without eliminating its efficiency benefits.
Why is runbook discoverability important for reducing MTTR?
Runbooks linked directly from alerts allow engineers to begin remediation immediately without searching documentation systems. Runbooks stored independently of the incident platform remain accessible even when primary tools fail, which directly reduces mean time to resolution.
What are the core stages of a network operational workflow?
The five core stages are telemetry data collection, centralized monitoring and visibility, incident detection and alerting, remediation (automated or manual), and post-incident analysis. Each stage feeds into the next, creating a continuous improvement loop.
How should organizations approach network workflow optimization?
Start by auditing existing processes against each workflow stage, identify gaps in documentation and governance, then introduce automation incrementally starting with low-risk, well-documented tasks. Network monitoring strategies and structured change management are the highest-leverage starting points.