
Most IT teams don't realize how much time they lose to tool sprawl until they audit it. The average enterprise runs 10 to 15 separate monitoring tools, each generating its own alerts, maintaining its own data model, and demanding its own login. Understanding why replace fragmented monitoring tools matters starts with recognizing that the problem is not just inconvenience. It is a measurable drain on incident response speed, security posture, and compliance readiness. This article gives IT professionals and decision-makers a clear, evidence-based case for consolidating their monitoring environments before the costs compound further.
Key Takeaways
| Point | Details |
|---|---|
| Fragmentation wastes time | Over a quarter of IT operational time is lost to false positives generated by inconsistent alert logic across siloed tools. |
| Security gaps widen | Fragmented telemetry limits AI and ML effectiveness, slowing threat detection and leaving compliance audit trails incomplete. |
| Unified platforms speed response | Organizations using unified platforms detect incidents 72 days sooner and mitigate them 84 days faster on average. |
| Phased migration reduces risk | Consolidating tool domains one at a time minimizes disruption and preserves critical workflows during transition. |
| Operational simplification has ROI | Reduced training overhead, fewer integrations to maintain, and standardized procedures translate directly into competitive efficiency gains. |
What fragmented monitoring tools actually look like
The industry term for this problem is "tool sprawl." Fragmented monitoring tools, informally, are the collection of point solutions that accumulate over time when teams add specialized tools to solve specific problems without a consolidation strategy. A network team deploys one platform for SNMP polling and bandwidth graphs. The application team adds another for APM. Cloud ops spins up a third for infrastructure metrics. Security installs a fourth for log aggregation. Before long, you have six dashboards, three alerting pipelines, and no single source of truth for anything.
This pattern persists for understandable reasons. Teams prioritize solving the immediate problem. Procurement cycles favor best-of-breed tools that score well in RFPs. Legacy workflows get embedded in vendor-specific alert rules nobody wants to migrate. The result is a monitoring stack that reflects the history of your organization's problems rather than the current structure of your infrastructure.
The specific challenges that emerge from this arrangement include:
- Inconsistent alert logic across tools that use different thresholds, severities, and escalation paths for similar events
- Siloed telemetry where metrics, logs, and traces live in separate systems with no shared correlation layer
- Duplicate notifications for the same underlying issue, routed to different teams with no unified ownership model
- Coverage gaps where the boundaries between tools create blind spots, particularly in hybrid or multi-cloud environments
- Fragmented documentation that forces engineers to cross-reference multiple systems to reconstruct incident timelines
The hidden cost of tool sprawl is rarely visible in any single budget line. It shows up in engineer hours, extended outages, and missed SLAs.
Operational inefficiency and the alert fatigue problem

Legacy monitoring systems rely on static thresholds and siloed data, which creates significant noise in modern distributed environments. When each tool generates alerts independently, with no shared context, your team ends up triaging the same incident multiple times across multiple platforms.
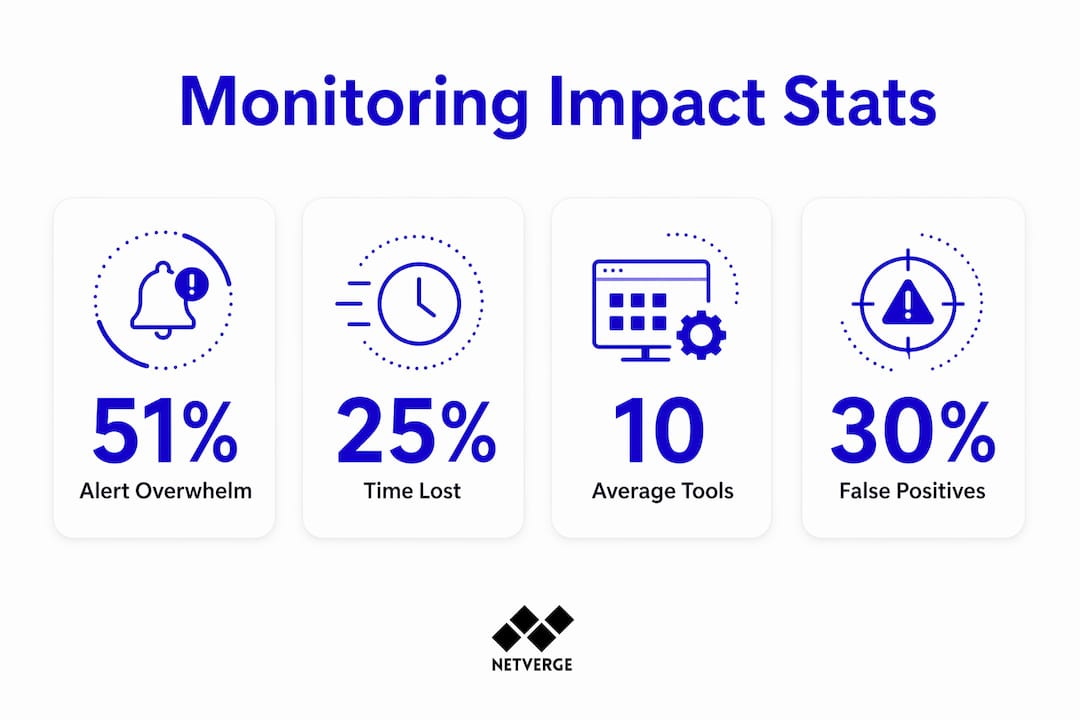
The data from 2026 is clear. 51% of IT teams report being overwhelmed by alert volume. More than a quarter of total IT operational time goes to chasing false positives generated by inconsistent alert logic across disconnected tools. That is not a minor inefficiency. For a 10-person NOC team, losing 25% of operational capacity to noise is the equivalent of running two engineers short every single day.
Manual correlation makes the problem worse during actual incidents. Fragmented workflows force engineers to move between dashboards, ticketing platforms, identity systems, and communication tools just to gather enough context to assign ownership. Every minute spent doing that manually is a minute your MTTR is climbing.
The specific operational risks that compound over time include:
- Delayed root cause analysis because correlated signals live in separate systems
- Unclear incident ownership when alerts from different tools point to different teams
- Alert suppression habits where engineers start ignoring low-severity notifications entirely
- Increased cognitive load that degrades decision quality during high-pressure incidents
Pro Tip: Before consolidating, run a one-week alert audit. Log every alert your team receives, which tool generated it, and whether it led to a real action. The ratio of actionable to ignored alerts will tell you exactly how much noise your current stack is producing.
This is also where alert fatigue hits MSP margins hardest. When your engineers spend half their shift triaging notifications that resolve themselves, you cannot scale client capacity without scaling headcount proportionally.
Security and compliance risks of fragmentation
The operational costs are significant. The security and compliance consequences are more serious.
Fragmented telemetry directly limits the effectiveness of AI and ML-based threat detection. Machine learning models depend on correlated, high-quality data across network, endpoint, application, and identity signals. When that data lives in separate tools with different schemas and collection intervals, the models see fragments rather than patterns. The detection surface narrows exactly where modern attacks are designed to exploit gaps.
The compliance picture is equally problematic. Fragmented data creates gaps and inconsistencies in audit trails that directly undermine your ability to meet regulations like NIS2 and the UK Cyber Resilience Act. When an auditor asks for a unified incident timeline, you cannot produce one from six tools that logged the same event differently.
The key security and compliance failure modes from fragmentation are:
- Incomplete audit trails where different tools capture overlapping but non-identical event records
- Threat correlation failures when attack vectors span network, application, and identity layers simultaneously
- Delayed incident reporting caused by manual aggregation of data from multiple platforms before a report can be generated
- Vendor lock-in exposure where proprietary data formats make future migration progressively harder and more expensive
Unified platforms unify telemetry, policy, analytics, and automation under a common data model, enabling cross-domain visibility that fragmented stacks cannot replicate. This is the architectural shift that makes compliance reporting and threat detection fundamentally more reliable. IDC
The vendor lock-in risk deserves attention. Best-of-breed tools often offer deeper functionality in their specific domain. But that depth comes with proprietary APIs, custom data schemas, and integration complexity that accumulates with every additional tool you add. The more tools you connect, the more brittle the integrations become, and the harder it is to move later.
Unified platforms vs. fragmented stacks: an honest comparison
The benefits of unified monitoring tools are measurable, not theoretical. Organizations that have consolidated onto unified platforms detect incidents 72 days sooner and mitigate them 84 days faster on average compared to best-of-breed tool stacks. That is not a marginal improvement. That is the difference between containing a breach and experiencing a reportable incident.
| Capability | Fragmented tools | Unified platform |
|---|---|---|
| Alert correlation | Manual, cross-tool | Automated, single data model |
| Compliance reporting | Fragmented, inconsistent | Centralized, audit-ready |
| Incident ownership | Unclear, multi-team | Defined, single workflow |
| AI/ML effectiveness | Limited by siloed data | Full telemetry correlation |
| Integration maintenance | High, vendor-specific | Low, vendor-managed |
| Onboarding and training | Per-tool, duplicated | Standardized across platform |
Operational simplification is consistently the most underappreciated benefit of this transition. Fewer tools mean fewer integrations to maintain, less training overhead, and standardized procedures that reduce cognitive load across your entire team.
That said, best-of-breed tools still make sense in specific scenarios. If your organization has a specialized security function that requires depth a unified platform cannot match, a targeted best-of-breed deployment is defensible. The critical discipline is treating it as a deliberate exception rather than the default approach.
Platform approaches shift integration workload to the vendor, simplify maintenance, and reduce the resource burden on your internal team. That is a structural advantage that compounds over time as your infrastructure grows.
Pro Tip: Map your current tool stack against your incident response playbook. Identify every step where an engineer has to switch tools to gather context. Each switch is a quantifiable delay. That map becomes your consolidation priority list.
How to replace fragmented tools without disrupting operations
A wholesale replacement strategy rarely works. Phased consolidation by domain reduces migration friction and preserves operational continuity while the new platform proves itself in production.
Here is a practical sequence for IT teams and MSPs:
Audit your current stack. Catalog every monitoring tool in use, what it covers, who owns it, and how many alerts it generates per week. Include tools managed by individual teams that may not appear in your official software inventory.
Identify overlap and gaps. Map coverage domains across tools. Look for areas where multiple tools monitor the same infrastructure and areas where no tool has visibility. Both are targets for consolidation.
Prioritize core network infrastructure first. Network-layer visibility should be the foundation. Consolidating SNMP, flow data, and uptime monitoring into a single platform before tackling application or cloud monitoring gives you a stable baseline with less disruption risk.
Select a platform with broad protocol and sensor support. The platform needs to cover your current protocols (SNMP, NetFlow, syslog, WMI, API polling) and your future needs. Hardware sensors that provide physical network visibility, similar to Netverge's Vergepoints, extend coverage to locations where agent-based monitoring is impractical.
Plan for organizational change. Tool consolidation changes workflows. Involve the teams that own current tools early. Establish clear runbooks before decommissioning anything, and run old and new tools in parallel during a validation period to build confidence before cutover.
My take on why this matters more than most teams realize
I've worked with enough IT organizations to know that fragmentation is almost never recognized as the root problem until after a serious incident. Teams describe their problems as "alert fatigue" or "slow incident response" or "compliance headaches." When you trace those problems back to their source, the common factor is almost always the same. Disconnected tools with no shared context.
What I find consistently underestimated is the cumulative security liability of fragmentation. It's not just that your team is slower. It's that your AI-based detection tools are working with incomplete inputs, your audit trails have gaps your compliance team doesn't know about yet, and your attack surface includes the integration points between your tools that nobody is actively monitoring.
The organizational readiness piece is equally important and equally underestimated. A unified platform that your team doesn't trust or understand will not deliver its potential. The consolidation project is a technical migration and a change management initiative simultaneously. Teams that treat it as purely technical run into resistance when they try to decommission familiar tools. The ones that succeed invest in training and communicate clearly about why each tool is being retired.
My read on the 2026 monitoring environment is that the window for addressing fragmentation proactively is narrowing. Regulatory requirements are getting more specific about audit trail completeness. Threat actors are specifically exploiting the gaps between monitoring domains. The cost of deferring consolidation is rising faster than the cost of executing it.
— Jim
See what unified monitoring looks like in practice
If you recognize your environment in this article, Netverge was built specifically to address the problem at its root.

Netverge unifies network visibility, documentation, ticketing, and automated troubleshooting into a single AI-powered platform. Its AI-powered monitoring correlates telemetry across your entire infrastructure, eliminating the manual context-switching that slows incident response in fragmented environments. Vergepoints hardware sensors extend physical visibility to every location, and autonomous AI agents diagnose and resolve issues automatically without requiring engineer intervention for common fault types.
For MSPs managing multiple client networks and for enterprises with distributed infrastructure, Netverge supports a phased consolidation approach that lets you retire tools systematically without disrupting active operations. You can explore network monitoring trends shaping 2026 or use the pricing calculator to estimate your cost. Request a demo to see the platform in your specific environment.
FAQ
What are fragmented monitoring tools?
Fragmented monitoring tools, also called tool sprawl, are collections of point solutions that monitor different infrastructure domains independently, without a shared data model or unified alert correlation layer. The result is siloed visibility, inconsistent alerts, and no single source of truth during incidents.
Why replace fragmented monitoring tools now?
Regulatory requirements under frameworks like NIS2 now demand complete, consistent audit trails that fragmented tools cannot produce reliably. At the same time, IT teams waste over a quarter of operational time on false positives, a direct cost that compounds as infrastructure scales.
What are the main benefits of unified monitoring tools?
Unified platforms provide automated alert correlation, centralized compliance reporting, consistent incident ownership, and significantly faster detection and mitigation. Organizations detect incidents an average of 72 days sooner compared to fragmented best-of-breed stacks.
How should IT teams start consolidating monitoring tools?
Start with an audit of your current tool stack to catalog coverage, ownership, and alert volume. Then prioritize core network infrastructure for consolidation before tackling application and cloud monitoring, and run old and new platforms in parallel during a validation period before decommissioning.
Does consolidating to a unified platform mean losing specialized functionality?
Not necessarily. A well-architected unified platform covers the majority of monitoring use cases with a common data model and broad protocol support. Best-of-breed tools remain justified only for highly specialized requirements that the platform demonstrably cannot meet. The integration complexity of maintaining exceptions, however, should be weighed carefully against the depth benefit they provide.