
Most IT teams don't suffer from too few network tools. They suffer from too many. The assumption that adding another dashboard, monitoring agent, or ticketing system improves coverage is one of the most persistent misconceptions in network operations. Understanding why replace fragmented network tools matters starts with recognizing that tool sprawl creates compounding inefficiencies: slower incident response, inconsistent data, and AI systems that simply can't function well without a reliable, unified context. With 73% of network professionals planning to replace at least some tools in the next two years, the industry is clearly reaching a breaking point.
Table of Contents
- Key Takeaways
- Why replace fragmented network tools now
- Strategic drivers behind tool replacement
- Unified platforms vs. best-of-breed tools
- Practical steps for replacing fragmented tools
- My take on what fragmentation actually costs
- See what a unified network platform looks like
- FAQ
Key Takeaways
| Point | Details |
|---|---|
| Tool fragmentation slows response | Manual context switching across disconnected dashboards increases incident response time and raises outage risk. |
| AI readiness requires unified data | Only 44% of teams are confident in their data quality, making fragmented environments a direct barrier to AI success. |
| Consolidation beats specialization at scale | Unified platforms shift normalization work to vendors and reduce detection times by weeks. |
| Replacement is a data project first | Successful tool consolidation depends on data discovery, validation, and governance before any software swap. |
| Strategic drivers are accelerating change | AI automation and hybrid cloud support are the top reasons network teams are replacing their current observability tools. |
Why replace fragmented network tools now
The industry term for what many organizations are dealing with is tool proliferation, and its effects go far beyond budget waste. When your network operations center relies on six different monitoring systems, a separate ticketing platform, and a standalone documentation tool that nobody keeps current, every incident becomes an exercise in manual correlation.
Fragmented workflows during incidents force responders to manually move between multiple dashboards just to build a picture of what is happening. That manual stitching takes time. Time you don't have when a circuit is down at a client site or a core switch is throwing errors across three locations.
Here are the specific operational pain points that fragmented toolsets create:
- Inconsistent visibility: Different tools report on different segments of the network, leaving gaps that only surface during outages. You often discover what you couldn't see right when it matters most.
- Slow incident response: Each tool speaks a different data format. Correlating telemetry from a flow analyzer, an SNMP poller, and a cloud monitoring agent requires manual effort that delays diagnosis.
- Low AI confidence: When your data lives in scattered repositories, the signal quality fed to any AI or automation layer degrades. Only 44% of teams report confidence in their network data quality to actually support AI-driven operations.
- Automation blockers: Scattered data repositories require extensive validation and reconciliation before any automation project can get off the ground, consuming engineering hours on cleanup instead of delivery.
- Knowledge silos: When documentation lives outside your monitoring context, engineers rely on tribal knowledge to interpret alerts. That knowledge walks out the door with every departure.
Pro Tip: Before evaluating any replacement platform, map every tool currently touching your network data. Include documentation systems, ticketing platforms, and even spreadsheets. You will almost certainly find more fragmentation than you expected, and that map becomes your consolidation roadmap.
The cumulative effect is an operations team that spends more time managing tools than managing the network. That's the real cost of fragmentation. It's not just a software licensing problem. It's an operational efficiency problem that scales with the complexity of your environment.
Strategic drivers behind tool replacement
Knowing the pain points is one thing. Understanding what is actually driving network teams to act is another. Recent research points to a clear set of motivators that explain why organizations are moving from fragmentation to consolidation now.
AI and automation adoption: 54% of network professionals cite AI-driven insights and automation as their primary motivation for replacing observability tools. A further 55% say AI capabilities are now a non-negotiable requirement when evaluating any new platform.
End-to-end visibility requirements: Distributed organizations managing hybrid and multi-cloud environments cannot rely on point solutions that only see one layer. The need for correlated visibility across network, application, cloud, and user experience telemetry is pushing teams toward platforms that aggregate data by design.
Hybrid and multi-cloud architecture support: Modern network architectures don't map neatly onto legacy monitoring tools built for on-premises infrastructure. Organizations need platforms that understand SD-WAN, cloud-native services, and physical hardware within a single operational context.
Day 2 operations automation: 26% of network managers identify automating Day 2 tasks, specifically troubleshooting, event management, and configuration remediation, as a top priority. This group is significantly more likely to be actively replacing their current toolsets.
Dissatisfaction with current solutions: Only 32% of network professionals report being fully satisfied with their existing tools. Dissatisfaction isn't passive. It converts directly into replacement decisions.
These drivers are not independent. They reinforce each other. An organization that wants to deploy AI-driven anomaly detection quickly realizes its fragmented data model is the actual blocker. That realization accelerates consolidation decisions in a way that cost savings alone never would. Improving network management efficiency increasingly means addressing the tool stack first.
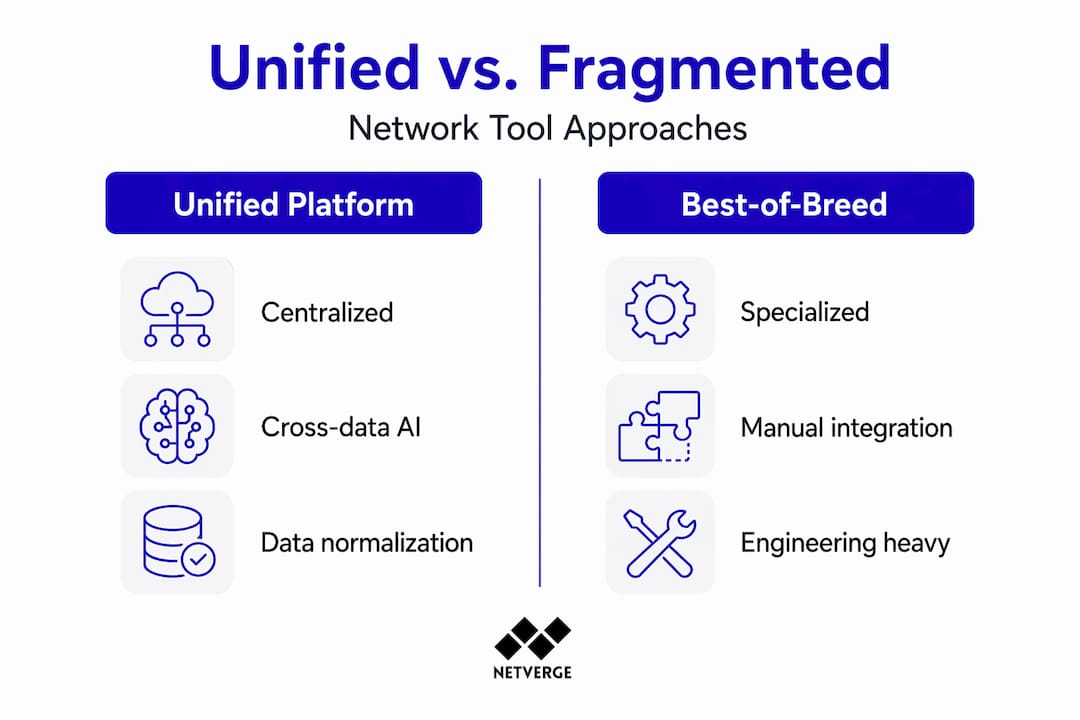
Unified platforms vs. best-of-breed tools
The debate between unified platforms and best-of-breed tools is real, and neither side gets to claim a clean win. What matters is understanding where each approach actually performs better and at what cost.

| Criterion | Unified platform | Best-of-breed tools |
|---|---|---|
| Data normalization | Handled by vendor across all modules | Manual integration and schema reconciliation required |
| Incident detection speed | Up to 72 fewer days to detect incidents | Slower due to correlation gaps |
| Incident mitigation speed | Up to 84 fewer days to mitigate on average | Delayed by manual triage across systems |
| AI/automation readiness | High: consistent data context supports model accuracy | Low: fragmented context degrades AI output quality |
| Specialization depth | Moderate: broad coverage with less per-domain depth | High: best-in-class capability per domain |
| Vendor risk | Higher dependency on single vendor roadmap | Distributed risk across multiple vendors |
| Operational complexity | Lower: single pane of glass management | Higher: multiple integrations, APIs, and update cycles |
| Cost structure | Predictable licensing; potential volume savings | Variable; integration costs often underestimated |
The best-of-breed argument holds when you need specialized capability in a narrow domain and have the engineering resources to maintain integrations. Most distributed organizations do not. They need coverage, speed, and AI readiness more than they need per-tool depth.
Unified vendors handle data normalization across heterogeneous environments, which is work your engineering team currently does manually or simply doesn't do at all. That shift in responsibility alone changes the operational calculus significantly.
The two real risks of consolidation are vendor lock-in and cultural resistance. Both are manageable with the right approach, but neither should be dismissed.
Pro Tip: When evaluating unified platforms, test their API export capabilities before committing. A platform that locks your data in a proprietary schema creates the same fragmentation problem at a different layer. Prioritize platforms with open telemetry standards and documented migration paths.
Practical steps for replacing fragmented tools
Replacing your current tool stack is not a procurement exercise. Treating it as a data curation and cultural transformation initiative produces far better outcomes than treating it as a software swap.
These are the steps that determine whether a consolidation project succeeds or stalls:
- Start with data discovery: Inventory every source of network data your team currently uses. This includes SNMP polls, flow data, syslog streams, IPAM systems, manual documentation, and cloud monitoring APIs. You cannot consolidate what you haven't mapped.
- Validate before you migrate: Data schema reconciliation and validation consistently dominate implementation timelines. Budget time for this upfront rather than treating it as a post-migration cleanup task.
- Secure cross-team buy-in early: Tool consolidation affects network engineers, security analysts, help desk staff, and management. Political resistance from teams that own incumbent tools is a real project risk. Involve stakeholders in evaluation, not just announcement.
- Consolidate domain by domain: Don't attempt a full-stack replacement in a single cutover. Start with one domain, such as physical network monitoring or cloud observability, validate the outcome, and expand. This approach limits blast radius when issues surface.
- Establish a consistent data model: Before enabling AI features, confirm that the platform applies a uniform data model across all ingested sources. Inconsistent context is the primary reason AI-driven network operations fall short of expectations.
Understanding network visibility steps before committing to a platform helps teams identify where their current gaps are most severe. The consolidation path becomes clearer when visibility requirements are defined first rather than assumed.
Pro Tip: Assign a data owner, not just a project manager, to your consolidation initiative. Someone needs accountability for data quality outcomes, not just deployment milestones. Without that role, data governance gaps persist regardless of which platform you select.
My take on what fragmentation actually costs
I've worked with a lot of distributed IT environments, and the most underestimated cost of tool fragmentation isn't the licensing fees or the integration maintenance. It's the cognitive overhead your best engineers absorb every single day.
When an incident fires, a skilled network engineer shouldn't be spending the first twenty minutes figuring out which tool has the relevant data and how to connect it to the ticket. Manual cross-system correlation is exactly what fragmented environments produce. And it compounds. The more complex your environment, the more time gets consumed before actual diagnosis begins.
What I've seen organizations consistently underestimate is the data quality work that sits behind any successful consolidation. They plan for the tool deployment. They don't plan for the months of reconciling conflicting IP address records, normalizing hostname conventions across acquired sites, or discovering that three tools were all collecting the same metric with slightly different calculations.
The gap between AI promise and operational reality in most organizations traces directly to this problem. Only 35% of organizations report complete success with AI-driven network management. The model isn't the issue. The inconsistent, fragmented context feeding the model is. AI outputs are only as reliable as the operational data behind them.
My honest take: the teams that get consolidation right treat it as a data engineering project that happens to involve a new platform, not a platform project that happens to touch some data. That reframe changes how they allocate time, budget, and accountability. It also produces better outcomes in twelve months than any best-of-breed tool combination ever delivered.
— Jim
See what a unified network platform looks like
If the patterns described in this article sound familiar, Netverge was built specifically to address them. The platform unifies network monitoring, documentation, ticketing, and AI-driven automation into a single interface, replacing the fragmented stack that slows your team down.

Netverge's AI agents provide real-time anomaly detection, automated troubleshooting, and intelligent ticket triage across distributed environments. Its AI-powered monitoring platform supports physical, hybrid, and multi-cloud networks with consistent telemetry collection across all layers. For MSPs managing multiple client environments, Netverge for MSPs delivers the multi-tenant visibility and automation that fragmented tools simply cannot provide. Vergepoints hardware extends physical observability to every site without additional integration complexity. If your team is ready to close the gaps, explore Netverge's enterprise solution and see how consolidated operations change daily workflows.
FAQ
What are the main issues with fragmented network tools?
Fragmented tools force engineers to manually correlate data across disconnected systems during incidents, slowing response times and increasing outage risk. They also degrade data quality, which undermines AI and automation initiatives.
Why is AI adoption driving network tool replacement?
54% of network professionals cite AI-driven insights as the primary motivation for replacing tools because fragmented environments produce inconsistent data that AI models cannot reliably interpret.
How do unified platforms improve incident response?
Consolidated platforms reduce incident detection time by an average of 72 fewer days and mitigation time by 84 days compared to best-of-breed approaches, largely because correlated data removes manual triage steps.
What should teams prioritize before replacing fragmented tools?
Data discovery and validation should come first. Schema reconciliation and source mapping consistently extend implementation timelines, so addressing data governance before platform migration prevents costly post-deployment cleanup.
How many organizations plan to replace network tools soon?
73% of network professionals expect to replace at least some of their current tools within two years, reflecting broad dissatisfaction with fragmented observability stacks.