
When we started building Artemis, we had a choice most agent platforms quietly sidestep.
Do we let an LLM drive the workflow — pick the tools, decide the order, execute the actions, summarise the result — and trust that the output "Done" means done? Or do we put the LLM inside the workflow, in a glass box, and let the workflow itself stay deterministic?
We chose the second. Not because LLMs are bad at reasoning. They are often excellent at it. We chose it because the moment an LLM is the thing that decides whether to push an ACL, which router to touch, whether the ticket is resolved — you are back in the bubble. You have built an agent that sounds exactly the same whether it is right or catastrophically wrong.
So Artemis is built on a simple principle: the LLM is a tool, not the runtime.
Let me show you what that means in practice.
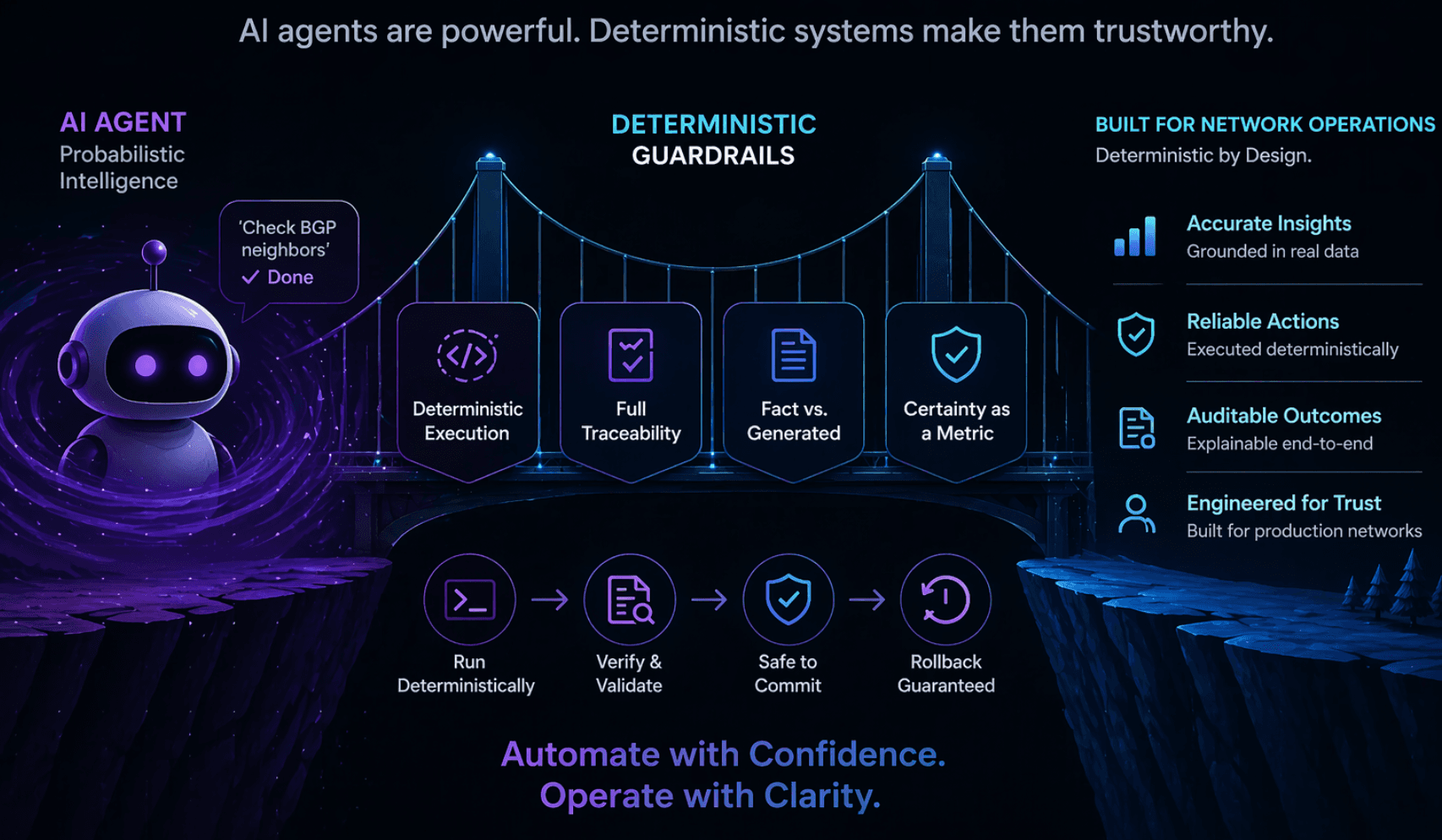
The shape of Artemis An Artemis workflow is not a prompt. It is a JSON graph of nodes and edges. Each node is a typed tool with an input schema and an output schema. The runner walks the graph in topological order, binds outputs of upstream nodes into the inputs of downstream nodes via explicit {{ $node..field }} references, and invokes each tool with validated arguments.
That is the entire execution model. There is no free-form agent loop. There is no "figure out what to do next." The graph is the plan. If a node is not in the graph, it does not run. If an edge is not drawn, data does not flow.
The LLM is called when — and only when — you explicitly place an llm_inquiry node in the graph and wire its output somewhere.
So why have an LLM at all? Because there is a genuinely hard class of problem where deterministic rules run out.
- Does this customer email describe a real outage or a configuration question?
- Summarise these 40 syslog lines for a human on Slack.
- Classify this ticket into one of five categories based on the body text, not the subject line.
- Given this stack trace and the asset's last-known config, what is the most likely root cause family?
You can write a regex. It will miss. You can write 200 regexes. They will miss more interestingly. You can write a Bayesian classifier. It will need labelled data you do not have.
An LLM dispatches these in one call, with context, at acceptable cost. That is real value. We would be silly to pretend otherwise.
So Artemis has an LLM. What it does not have is an LLM that gets to pretend it is the runtime.
How the LLM is kept sober The LLM node in Artemis (ArtemisLLMInquiryTool) is designed around one assumption: anything it produces is probabilistic until proven otherwise.
That assumption shows up in four concrete places.
- Typed output variables, not free-form text When you use an LLM to decide something downstream, you do not get a paragraph. You declare what you want back:
output_variables:
[
{"key": "priority", "type": "choice", "choices": ["low", "medium", "high", "critical"]},
{"key": "category", "type": "choice", "choices": ["network", "hardware", "software", "other"]},
{"key": "is_urgent", "type": "boolean"},
{"key": "confidence", "type": "confidence"}, # 0.0 to 1.0
{"key": "summary", "type": "text"}
]
The tool generates a prompt suffix that tells the model exactly which keys, which types, and which enum values are allowed. Then the response is validated against that schema (_validate_output_variables). If the LLM returns "priority": "urgent" — not in the enum — it is an error, not a surprise. A repair prompt is issued. If it still fails after max_validation_retries, the tool returns a real error status. No "Done."
The difference between "high" and "urgent" might seem cosmetic. It is not. It is the difference between a downstream switch node correctly routing to the P1 escalation branch, and silently falling through to the default branch because no case matched.
- Deterministic routing, not LLM-driven execution Here is the part that matters most. An llm_inquiry node produces structured fields. It does not decide what happens next.
What happens next is decided by a switch or filter node — pure, deterministic, auditable — that reads the LLM's typed output and routes accordingly. The LLM can suggest "this is a P1". The workflow graph is what acts on that suggestion, and only in branches the author drew.
The tool's docstring says it directly:
"This tool intentionally does NOT emit flow-control signals. Use dedicated gating/routing tools (filter/switch) based on your chosen output variables."
In plain English: the LLM does not get to invent control flow. If there is no branch to shutdown_edge_router, the LLM cannot create one by sounding confident about it.
- Fact and generated, clearly labelled Every node writes its output under its own namespace. In the workflow, data flows through explicit references:
{{ $node.get_ticket.ticket.subject }} — read from the database. Fact.
{{ $node.ssh_run_show.stdout }} — read from a real device over SSH. Fact.
{{ $node.classify_with_llm.json.priority }} — LLM interpretation. Generated.
A workflow author, and anyone auditing the workflow afterwards, can see by the node type and namespace whether a value came from a deterministic read or a probabilistic interpretation. The runner does not blur them into one "result" field the way a chat-style agent would.
When an Artemis workflow tells a human "this link is saturated", you can trace back through the graph to whether that claim came from ssh_command running show interfaces counters — or from an LLM inferring saturation from a ticket body. Both are legitimate. They are not the same thing. The workflow shows you which.
- Confidence as a first-class field confidence is not an afterthought. It is a first-class type in Artemis ("type": "confidence", range 0.0-1.0, validated). Structured output has it in the canonical envelope. The text_classifier tool requires it.
That means downstream nodes can do things like:
filter: only proceed if $node.classify.json.confidence >= 0.8 switch: if confidence < 0.6, route to human-review branch The LLM's own self-reported uncertainty becomes a routable signal. Low confidence does not mean "do nothing" — it means "do the thing that matches low confidence", which is usually handing it to a person via wait_for_confirmation.
Which brings me to the last piece.
The human still owns the commit Artemis has a tool called wait_for_confirmation. It pauses the workflow, persists state, and waits for a human to approve or reject a proposed action. It is deliberately a control-category tool, not an LLM one.
A typical sensitive workflow looks like:
- get_ticket — pull the change request. Fact.
- ssh_command — gather current state from the device. Fact.
- llm_inquiry — analyse, classify, summarise, propose. Generated, labelled, validated, typed, confidence-scored.
- switch — if confidence < threshold OR category is "invasive", route to the human branch. Deterministic.
- wait_for_confirmation — show a human the proposed change and the evidence. Human.
- ssh_command — apply the change. Fact. Real commit. Real rollback on error.
The LLM is in step 3. Every other step is deterministic. The LLM's influence on the world is bounded by the graph the author drew and the structured fields they agreed to accept. If the LLM hallucinates a P1, the worst it can do is trigger a human notification with the wrong priority label — not silently null-route the environemt.
The bigger point
One of our published article argued that you cannot tell, from inside the bubble, when you are on solid ground and when you are not. That is true of any system whose interface layer is a fluent LLM. The fix is not to stop using LLMs. The fix is to build a scaffold around them where:
The LLM proposes, the workflow disposes. Execution is deterministic, even when reasoning is not. Output is typed, validated, and namespaced, so "what was said" and "what was done" are different questions with different answers.
**Certainty is a signal, not an aesthetic. **
Humans own the irreversible commits, by default, until proven otherwise for a specific workflow. Artemis is our answer to that. It is not the only valid answer. But it is built on the bet that the agents worth trusting in production will be the ones where you can draw a clear line around the probabilistic part, label it, validate it, and make it earn its way into a deterministic action — every time, on every run, with a graph you can read.
The smartest agent will not win. The agent you can hand a change window to at 3am will.
We are building for 3am.